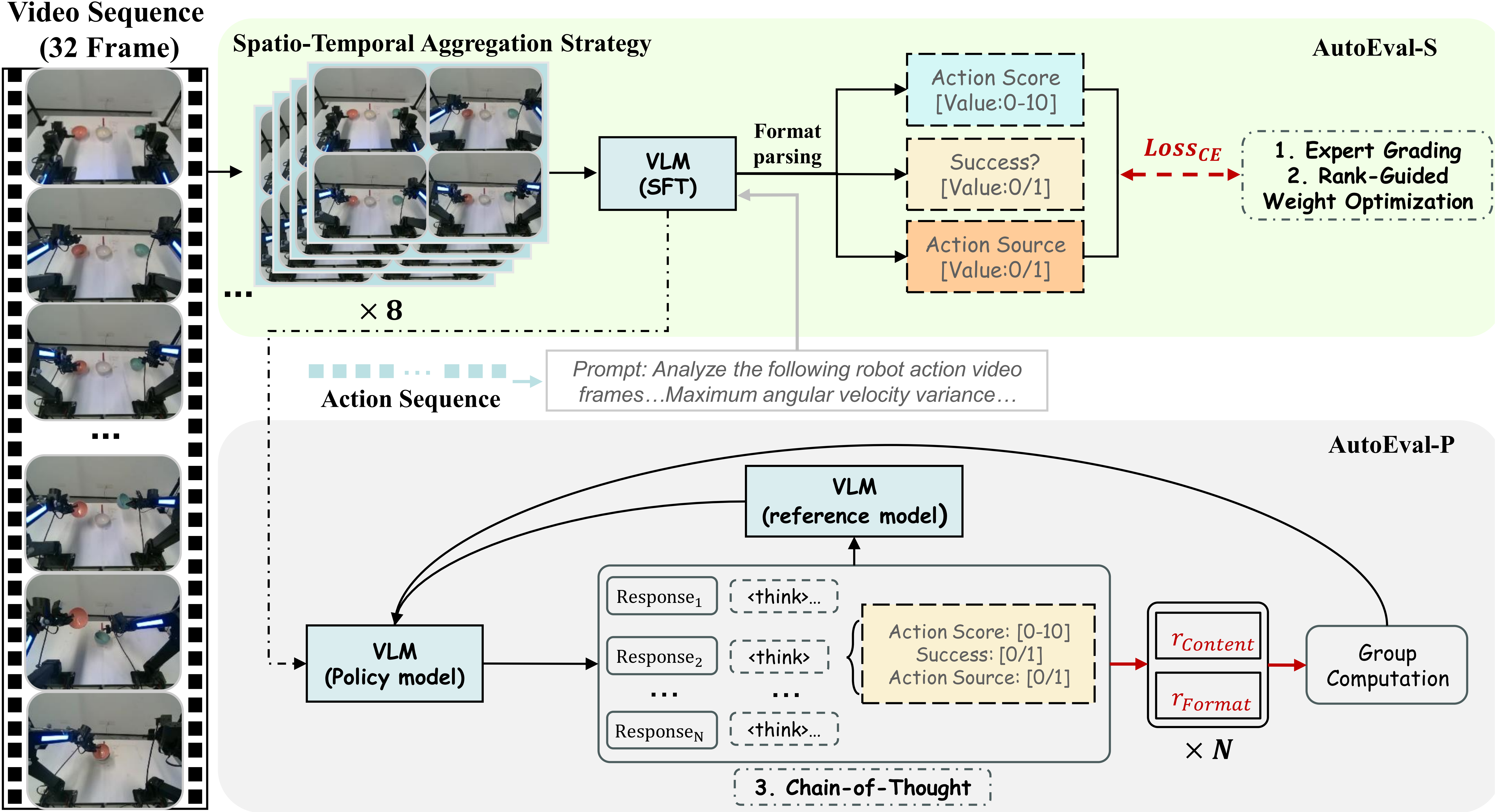
Motivation
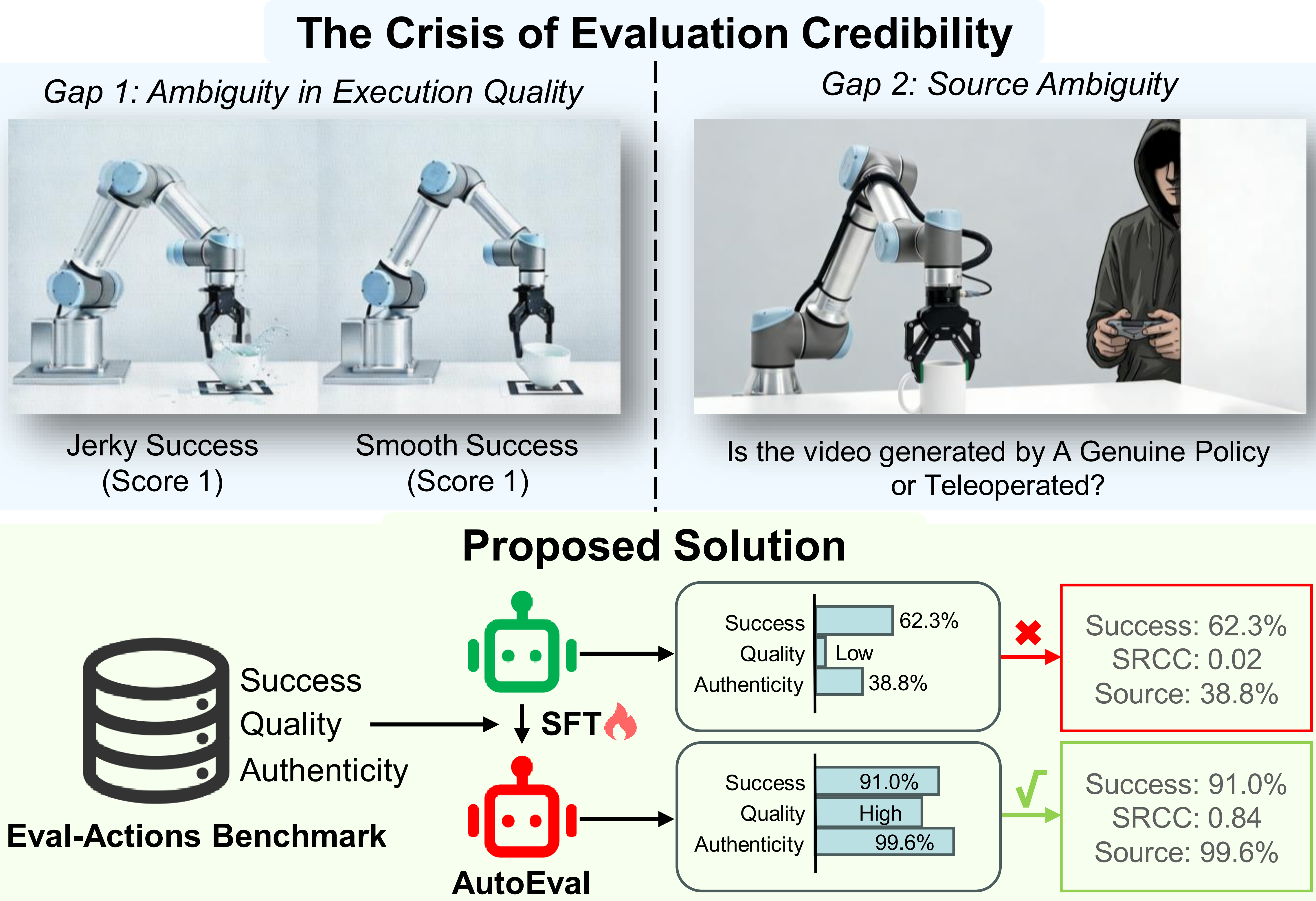
Figure 1. The Crisis of Evaluation Credibility and the Proposed Trustworthy Evaluation Solution. (Top) The Crisis: We identify two critical sources of ambiguity obstructing trustworthy evaluation: Gap 1 (Ambiguity in Execution Quality), where binary metrics mask shaky or unsafe execution (visualized as ''Jerky Success'' vs. ''Smooth Success''), and Gap 2 (Ambiguity in Source Authenticity), where the provenance of ''successful'' demonstrations is unverifiable. (Bottom) Proposed Solution: Our Trustworthy Evaluation Framework bridges these gaps. Powered by the Eval-Actions Benchmark and the AutoEval Architecture (depicted as the green robot optimized via Supervised Fine-Tuning (SFT)), the system achieves precise Fine-Grained Action Quality assessment (SRCC 0.84) and robust Source Authenticity verification (99.6%), as shown in the green box. This significantly outperforms standard Vision-Language Models (VLMs) without SFT (red box) to ensure evaluation credibility.